A benchmark to unify virtual try-on, virtual try-off
and instruction-based editing
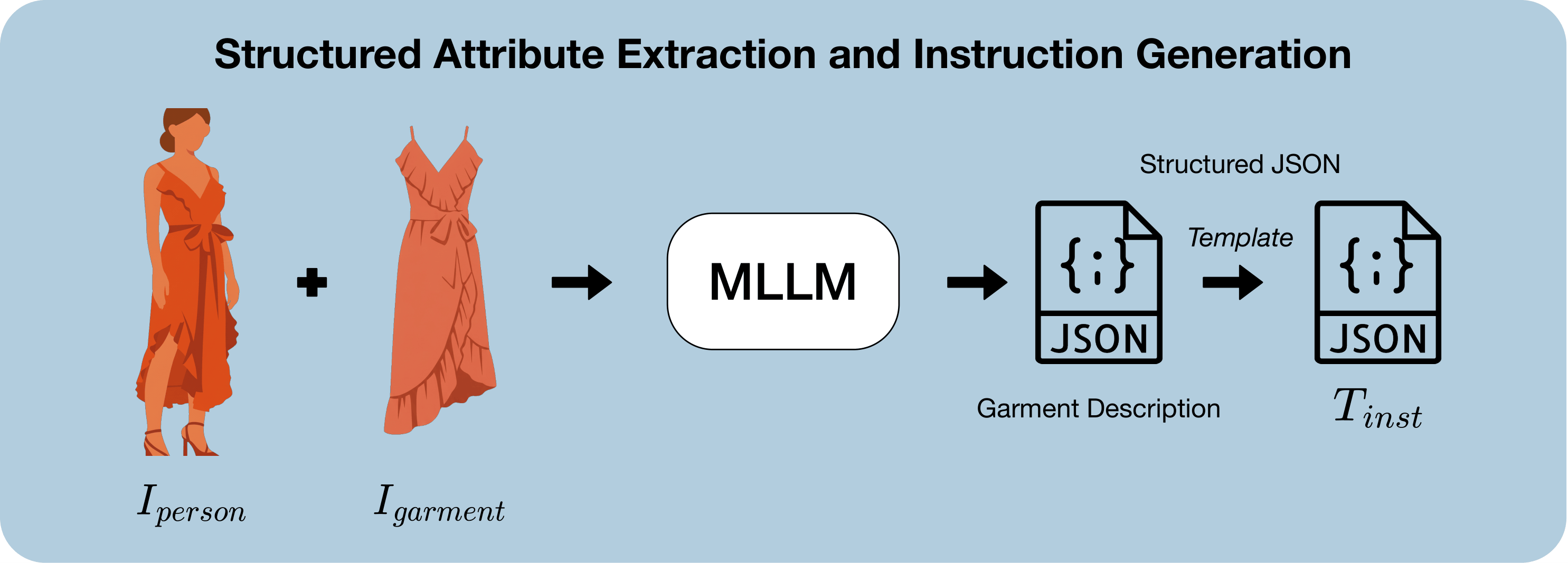
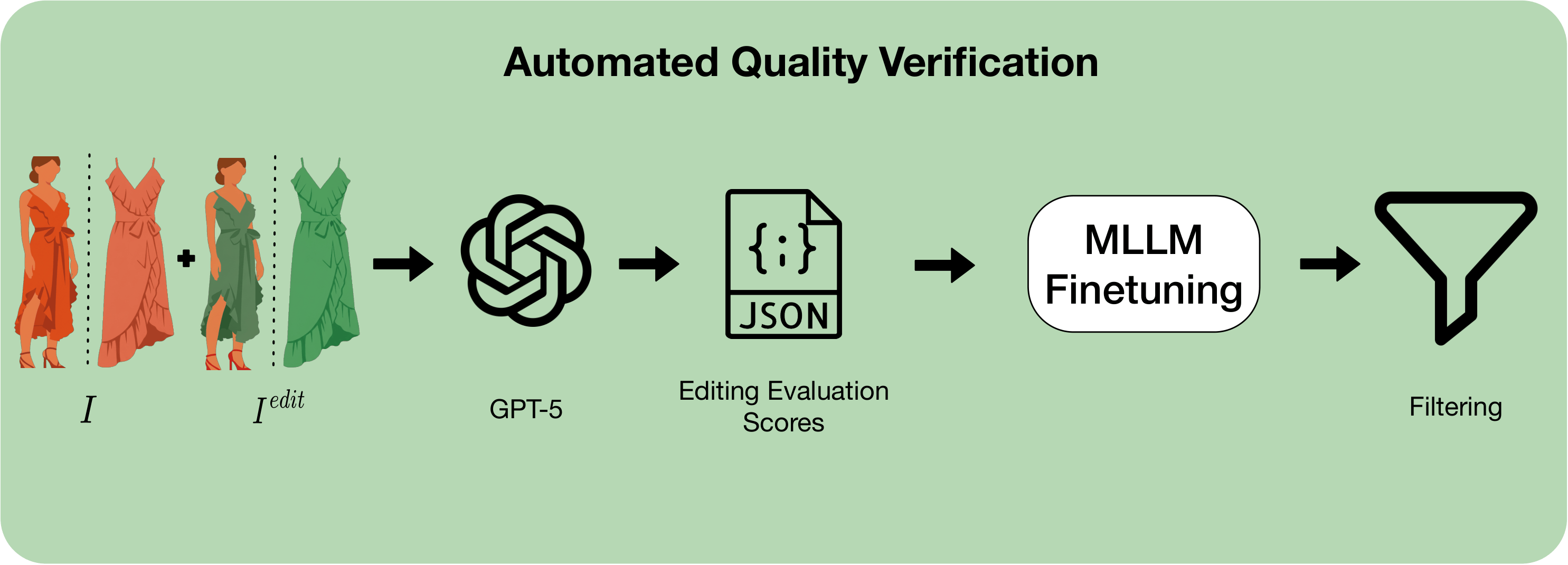
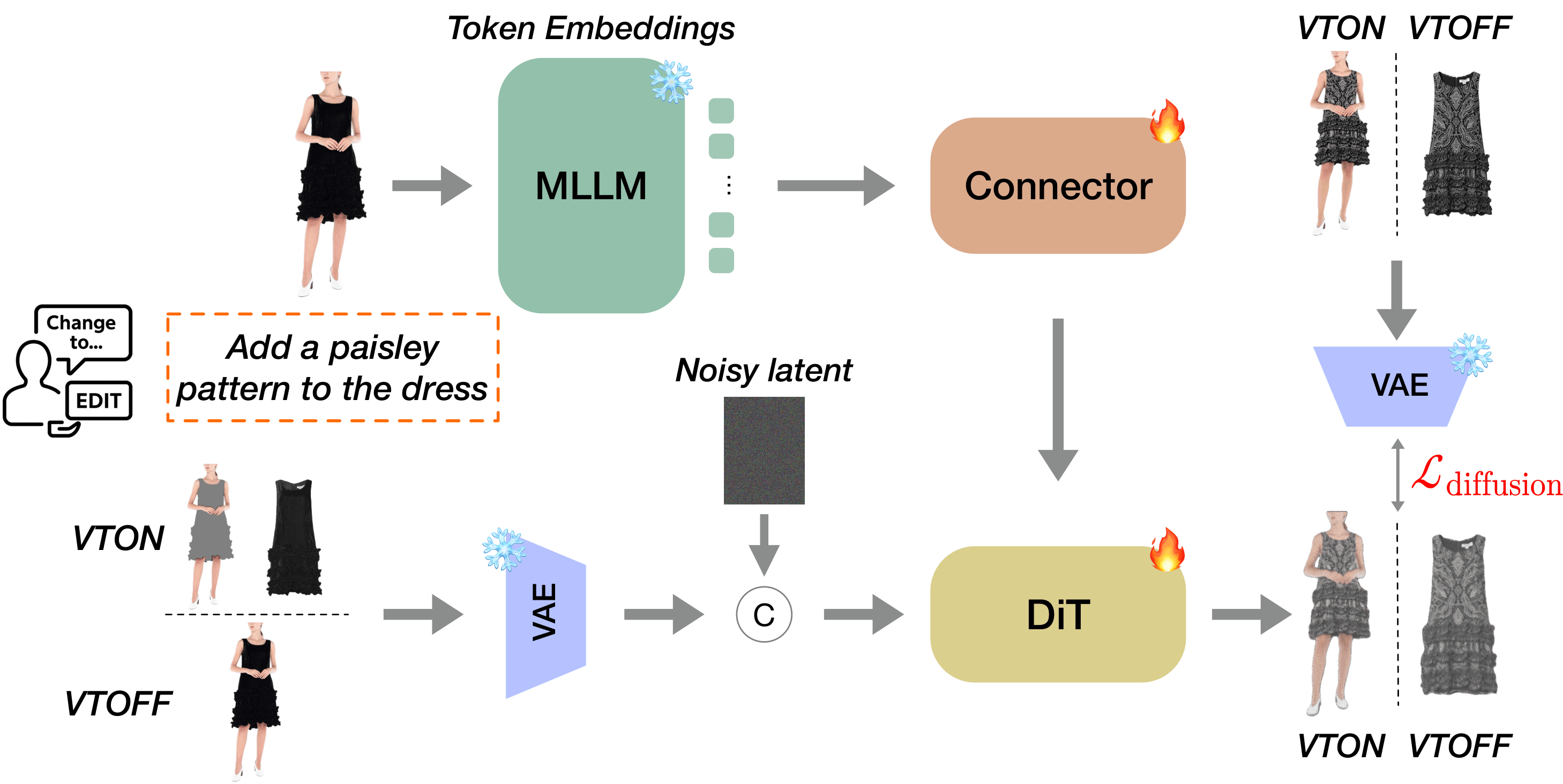
We present Dress-ED, the first large-scale benchmark unifying VTON, VTOFF, and text-guided garment editing within a single, semantically consistent framework — driven by natural language. No prior dataset jointly supports instruction-driven VTON and VTOFF. Dress-ED defines this task from scratch, providing 146,460 verified quadruplets across 7 edit types and 3 garment categories. Quality is ensured by a 4-stage automated pipeline that achieves 95.6% human-model agreement. Alongside the benchmark, we introduce Dress-EM, a unified multimodal diffusion baseline applicable to both VTON and VTOFF, which outperforms all baselines across all tasks and metrics.
Figure 1. Dress-ED unifies VTON, VTOFF, and text-guided garment editing within a single semantically consistent framework.